── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.1 ✔ stringr 1.6.0
✔ ggplot2 4.0.1 ✔ tibble 3.3.0
✔ lubridate 1.9.4 ✔ tidyr 1.3.1
✔ purrr 1.2.0
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors7 综合指数测算
适用于数学建模、经济计量中测算,比如数字经济、就业质量、新质生产力等。
简单流程:
- 构建(三级)指标体系
- 搜集指标数据,预处理:正向化、归一化/标准化等
- 熵权法:计算三级指标权重
- 向上加权合成到二级指标值
- 熵权法:计算二级指标权重
- 向上加权合成到一级指标值
当然,也可以改进,比如赋权法用主客观组合赋权;融入评价算法:TOPSIS 等(注意:不适合后续接回归分析!)。
下面以测算 2020-2022 年 30 个省份的就业质量为例。
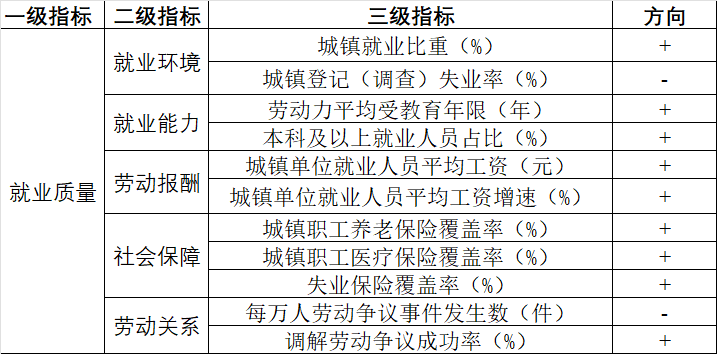
Rows: 90
Columns: 13
$ 年份 <dbl> 2022, 2022, 2022, 2022, 2022, 2022…
$ 地区 <chr> "北京", "天津", "河北", "山西", "内蒙古", "辽宁…
$ `城镇就业比重(%)` <dbl> 87.54417, 83.41385, 58.74302, 59.0…
$ `城镇登记(调查)失业率(%)` <dbl> 3.12, 4.68, 3.60, 5.50, 6.00, 5.30…
$ `劳动力平均受教育年限(年)` <dbl> 13.050, 11.604, 9.333, 9.880, 9.62…
$ `本科及以上就业人员占比(%)` <dbl> 46.9, 30.7, 9.5, 12.6, 14.9, 15.5,…
$ `城镇单位就业人员平均工资(元)` <dbl> 208977, 129522, 90745, 90495, 1009…
$ `城镇单位就业人员平均工资增速(%)` <dbl> 7.359839, 4.852341, 9.959286, 9.80…
$ `城镇职工养老保险覆盖率(%)` <dbl> 155.35822, 107.41313, 64.87874, 76…
$ `城镇职工医疗保险覆盖率(%)` <dbl> 117.50757, 80.50193, 40.99857, 50.…
$ `失业保险覆盖率(%)` <dbl> 140.40363, 75.71429, 37.82216, 53.…
$ `每万人劳动争议事件发生数(件)` <dbl> 131.44904, 56.83398, 15.30908, 14.…
$ `调解劳动争议成功率(%)` <dbl> 94.61831, 96.42046, 99.54734, 98.5…7.1 熵权法赋权 + 综合得分
指标数据预处理:量纲一致,方向一致。
熵权法,是一种根据各项指标数据所提供的信息量大小(离散程度)来确定指标权重的客观赋权法。
注意,熵权法已内置归一化,要避免做两次归一化。
准备指标方向向量:NA 表示不做内置归一化,"+" 表示做内置正向归一化,"-" 表示做内置负向归一化。
(1) 三级指标向上合成到二级指标
- 读取指标体系数据,按二级指标切分,据此就能分别取出每组的三级指标数据和方向向量
-
map循环迭代就能批量执行该层级上的所有熵权法,提取各三级指标的熵权权重
- 提取三级指标权重
# A tibble: 11 × 2
三级指标 熵权权重
<chr> <dbl>
1 城镇就业比重(%) 0.846
2 城镇登记(调查)失业率(%) 0.154
3 劳动力平均受教育年限(年) 0.260
4 本科及以上就业人员占比(%) 0.740
5 城镇单位就业人员平均工资(元) 0.813
6 城镇单位就业人员平均工资增速(%) 0.187
7 城镇职工养老保险覆盖率(%) 0.194
8 城镇职工医疗保险覆盖率(%) 0.408
9 失业保险覆盖率(%) 0.398
10 每万人劳动争议事件发生数(件) 0.327
11 调解劳动争议成功率(%) 0.673- 提取二级指标的综合得分,合并到数据框
(2) 二级指标向上合成到一级指标
- 执行熵权法,提取各二级指标熵权权重
就业环境 就业能力 劳动报酬 社会保障 劳动关系
0.17080626 0.33165581 0.20987609 0.21058484 0.07707701 - 提取一级指标综合得分
# A tibble: 90 × 8
年份 地区 就业环境 就业能力 劳动报酬 社会保障 劳动关系 就业质量
<dbl> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 2022 北京 96.9 99.8 87.1 91.5 33.6 90.4
2 2022 天津 85.2 63.0 38.7 48.1 65.2 58.2
3 2022 河北 37.4 13.1 22.9 13.7 96.6 24.3
4 2022 山西 33.9 21.4 22.6 24.4 90.4 28.1
5 2022 内蒙古 39.1 24.4 30.9 21.4 87.6 31.0
6 2022 辽宁 50.8 26.5 21.0 28.8 80.1 32.5
7 2022 吉林 34.6 22.1 14.9 20.2 68.4 23.2
8 2022 黑龙江 45.6 19.7 21.3 26.1 85.8 29.3
9 2022 上海 84.4 75.1 93.3 53.8 51.7 74.7
10 2022 江苏 64.3 24.7 35.4 33.3 78.9 38.8
# ℹ 80 more rows其它支持的客观赋权法还有:pca_weight()(PCA 赋权)、critic_weight()(CRITIC 赋权)。
7.2 主客观组合赋权 + 综合得分
若想让一级指标得分更有实际意义,应该将主观权重纳入考量。
层次分析法,通过综合两两比较各指标相对重要程度来确定指标权重的主观赋权法。
(1) 三级指标向上合成到二级指标
- 问 AI 得到的该层级上各判断矩阵,批量执行 AHP
- 提取各一致性比率,要求一致性比率 \(< 0.1\),否则需要调整判断矩阵
- 提取各三级指标的 AHP 权重
- 基于博弈论法批量组合各组主客观权重
- 合并三级指标的三种权重结果
# A tibble: 11 × 5
二级指标 三级指标 熵权重 AHP权重 组合权重
<fct> <chr> <dbl> <dbl> <dbl>
1 就业环境 城镇就业比重(%) 0.846 0.25 0.575
2 就业环境 城镇登记(调查)失业率(%) 0.154 0.75 0.425
3 就业能力 劳动力平均受教育年限(年) 0.260 0.75 0.507
4 就业能力 本科及以上就业人员占比(%) 0.740 0.25 0.493
5 劳动报酬 城镇单位就业人员平均工资(元) 0.813 0.75 0.783
6 劳动报酬 城镇单位就业人员平均工资增速(%) 0.187 0.25 0.217
7 社会保障 城镇职工养老保险覆盖率(%) 0.194 0.540 0.349
8 社会保障 城镇职工医疗保险覆盖率(%) 0.408 0.297 0.376
9 社会保障 失业保险覆盖率(%) 0.398 0.163 0.275
10 劳动关系 每万人劳动争议事件发生数(件) 0.327 0.75 0.547
11 劳动关系 调解劳动争议成功率(%) 0.673 0.25 0.453- 批量计算:每组三级指标向上合成到二级指标值,注意三级指标值需要先做归一化。
(2) 二级指标向上合成到一级指标
- 计算各二级指标熵权权重
- 问 AI 得到该层级的判断矩阵,执行 AHP,提取一致性比率
[1] 0.03715787- 提取 AHP 权重
- 基于博弈论法组合主客观权重
- 合并二级指标的三种权重结果
# A tibble: 5 × 4
二级指标 熵权权重 AHP权重 组合权重
<chr> <dbl> <dbl> <dbl>
1 就业环境 0.159 0.0604 0.104
2 就业能力 0.303 0.122 0.203
3 劳动报酬 0.257 0.467 0.366
4 社会保障 0.229 0.236 0.246
5 劳动关系 0.0525 0.114 0.0818- 向上加权合成到一级指标值
# A tibble: 90 × 8
年份 地区 就业环境 就业能力 劳动报酬 社会保障 劳动关系 就业质量
<dbl> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 2022 北京 92.1 100 85.6 92.3 22.6 85.7
2 2022 天津 77.0 66.3 38.2 50.1 63.9 53.0
3 2022 河北 49.3 18.5 24.2 14.9 96.2 29.3
4 2022 山西 38.3 27.6 23.8 25.3 92.3 32.1
5 2022 内蒙古 39.6 28.0 32.3 23.4 86.6 34.4
6 2022 辽宁 50.8 30.6 21.8 31.5 82.4 33.9
7 2022 吉林 47.0 25.6 15.2 22.7 78.0 27.6
8 2022 黑龙江 56.2 24.1 22.6 31.6 86.0 33.8
9 2022 上海 57.5 77.2 92.4 52.9 56.4 73.0
10 2022 江苏 63.1 29.3 35.2 33.1 80.2 40.0
# ℹ 80 more rows