mathmodels 包使用手册
化繁为简的数学建模利器
前言
这是与 mathmodels 包配套的中文使用手册1,内容整合自该包的 vignettes,目前只完整包含评价类算法。
Github 在线书:https://zhjx19.github.io/mathmodels-book/
mathmodels 包与本配套使用手册的核心特色
1. 全面覆盖评价类算法
| 算法 | 函数 |
|---|---|
| 指标数据预处理 | standardize()/normalize()/rescale_middle()/rescale_interval()/rescale_extreme()/rescale_initial()/rescale_mean()/to_positive() |
| 层次分析法 (AHP) | AHP() |
| 熵权法 | entropy_weight() |
| CRITIC 赋权 | critic_weight() |
| PCA 赋权 | pca_weight() |
| 主客观组合赋权 | combine_weights() |
| TOPSIS | topsis() |
| 灰色关联分析 (GRA) | grey_corr()/grey_corr_topsis() |
| 秩和比法 (RSR) | rank_sum_ratio() |
| 模糊综合评价 (FCE) | fuzzy_eval()/defuzzify()/compute_mf()/tri_mf()/trap_mf()/gauss_mf()/gbell_mf()/gauss2mf()/sigmoid_mf()/dsigmoid_mf()/psigmoid_mf()/z_mf()/pi_mf()/s_mf()/plot_mf() |
| 数据包络分析 (DDC/BCC/SBM, Malmquist) | basic_DEA()/super_DEA()/basic_SBM()/super_SBM()/malmquist() |
| 不平等度量:基尼系数、泰尔指数及其分解 | gini0()/gini()/theil0()/theil()/theil0_g()/theil_g()/theil_g2_cross()/theil_g2_nest() |
| 区域经济 (LQ, HHI, EG 指数) | LQ()/HHI()/EG() |
| 系统评价:耦合协调度、障碍度 | coupling_degree()/obstacle_degree() |
2. tidyverse 生态无缝衔接
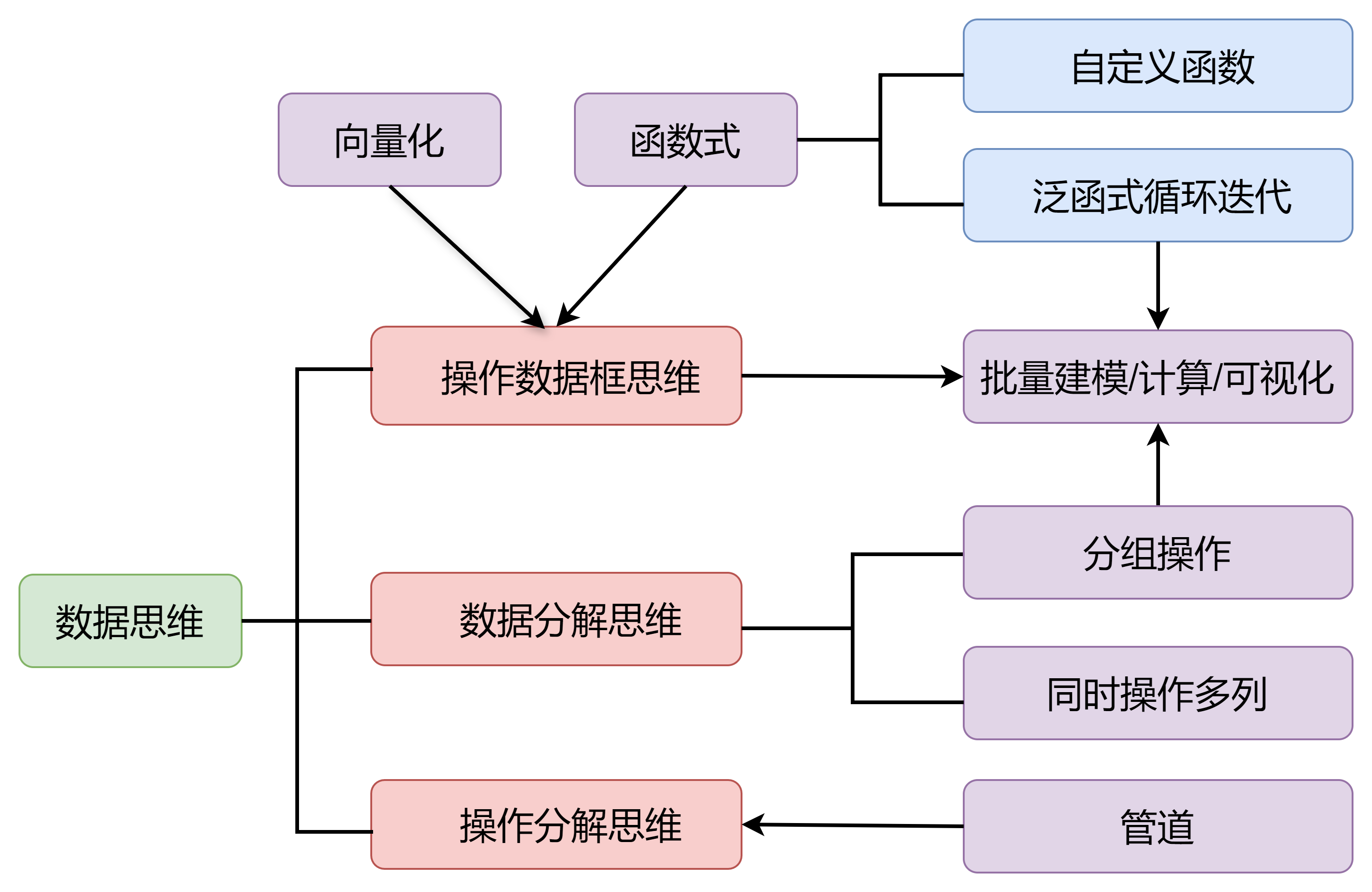
实际使用数学建模算法的最大痛点,往往都是批量应用算法,比如
- 层次分析法整个层次结构嵌套了多个子结构,而
AHP()只解决一个子结构 - 计算每个行业每年份内省份间工资的不平等程度(基尼系数)
- ……
这就需要从整洁数据开始,纳入 tidyverse 强大的数据编程思维:map 泛函式循环迭代、分组修改/汇总、分组嵌套等批量建模技术。
mathmodels 包通过精心设计函数接口,可与 tidyverse 生态的无缝衔接,显著提升了数学建模算法的易用性和批量处理效率。其核心设计理念是将算法封装为标准化函数,并通过两种策略实现与 tidyverse 工作流的深度结合:
(1) 函数专注单一计算,外部接入 tidyverse 实现批量应用
设计特点:每个函数聚焦独立算法(如数据预处理、权重计算、评价模型),输入输出标准化,便于嵌入 tidyverse 管道操作。
典型应用场景:
-
数据预处理:结合
mutate() + across()批量预处理多列指标
-
批量建模I:使用
map()循环迭代
-
批量建模II:通过
summarise(..., .by)分组应用算法
- 批量建模III:分组嵌套,每个嵌套数据框应用算法,再解除嵌套
(2) 将 tidyverse 数据思维融入函数内部
设计特点:函数内部直接整合分组操作,用户无需额外代码即可处理分组数据。
典型函数示例:
- 秩和比法:
rank_sum_ratio()中间步骤涉及诸多数据操作(用户无感知) - 泰尔指数分解:
theil_g()等直接支持分组计算,自动返回组间/组内不平等分解结果。 - 区位商:
LQ()提供.by参数,可选分组计算(比如各年份)区位商 - EG 指数:
EG()内部计算总量和分组占比,返回批量的 EG 指数。
另外,完美支持 |> 管道操作,将复杂问题分解为依次解决的若干简单问题,代码简洁流畅。
3. 算法实现精益求精
-
每个函数的输入(参数)、输出(返回值)都经过精心设计,充分考虑:
- 实用性、易用性,比如与
tidyverse结合,比如泰尔指数及其分解结果直接到可用于论文的表格 - 易被忽略的细节,比如避免中心型、区间型指标做两次归一化;
- 实用性、易用性,比如与
注重算法的简单化、流程化实现,比如模糊综合评价通过提炼
compute_mf()函数,成功将代码量减少了十倍。
4. 教学科研双重价值
- 理论扎实可靠:所有算法基于《数学建模:算法与编程实现》教材或经典文献;
- 完整配套资源:整合包的 vignettes 以在线书籍形式呈现,构成完整学习体系;
- 案例驱动学习:丰富的真实案例帮助用户快速掌握算法应用;
- 学术研究利器:为数学建模师生或科研工作者提供可靠、高效的算法工具箱。
总之,这套完整的解决方案将复杂的数学建模算法转化为简单易用的 R 工具,让数学建模师生或科研工作者能够专注于解决实际问题,而非算法实现的细节。
关于 mathmodels 包(当前 0.0.7 版本)
mathmodels 包是一个功能丰富的 R 语言数学建模包,专为《数学建模:算法与编程实现》[1](机械工业出版社)配套开发。该包计划涵盖微分方程与差分方程、统计分析、优化、评价和预测等多个领域的算法实现。当前版本重点实现评价类算法,主要包括:指标数据预处理(标准化、归一化等)、主客观赋权方法(层次分析法、熵权法、CRITIC 法、主成分法)及主客观组合赋权、综合评价方法(TOPSIS 法、模糊综合评价法、秩和比法、数据包络分析(DEA, SBM, Malmquist)、不平等测度(基尼系数、泰尔指数)、区域经济(LQ、HHI、EG指数)、系统评价(耦合协调度、障碍度)以及灰色预测模型(GM(1,1)、GM(1,N)、Verhulst 模型)等。本包面向广大数学建模师生和科研工作者而设计,提供便捷高效的算法工具支持。
可从 Github 安装:
或下载到本地解压到当前路径安装(若需要,先安装依赖包:lpSolveAPI 包):


更多学习资源
欢迎关注我的知乎,公众号:R 语言与数学建模,B 站:张敬信老师
欢迎加入我的个人知识库,里面有所有整理好的我出品的基于 tidyverse/mlr3verse 的全网最新的 R 语言编程、R 机器学习、数学建模相关学习、案例资料,可以下载,可以 DeepSeek 问答:
使用黄湘云提供的
quarto中文书籍模板编写.↩︎